Introduction
此为MIT 6.S081课程和xv6-Books的学习笔记
操作系统必须满足的三个要求:
- 多路复用(并发)
- 隔离
- 交互
Abstracting physical resources
当谈及操作系统时,人们可能会问的第一个问题是为什么需要对系统资源进行抽象?为了实现强隔离(安全性、容错性和健壮性),最好禁止应用程序直接访问敏感的硬件资源,而是将资源抽象为服务(换句话说抽象系统资源使得提供强隔离性成为了可能)。
What would happen if there is no OS or isolation?
通过下面CPU的例子来说明这个问题(actually this is quite easy to understand)
内存就更好理解了(“内存覆盖/溢出”)
通常来说,如果没有操作系统,应用程序会直接与硬件交互。比如,应用程序可以直接看到CPU的多个核,看到磁盘,内存。所以现在应用程序和硬件资源之间没有一个额外的抽象层,如下图所示。

这种设计是如何破坏隔离性的呢?使用操作系统的一个目的是为了同时运行多个应用程序,所以时不时的,CPU会从一个应用程序切换到另一个应用程序。我们假设硬件资源里只有一个CPU核,并且我们现在在这个CPU核上运行Shell。但是时不时的,也需要让其他的应用程序也可以运行。现在我们没有操作系统来帮我们完成切换,所以Shell就需要时不时的释放CPU资源。为了不变成一个恶意程序,Shell在发现自己运行了一段时间之后,需要让别的程序也有机会能运行。这种机制有时候称为协同调度(Cooperative Scheduling)。但是这里的场景并没有很好的隔离性,比如说Shell中的某个函数有一个死循环,那么Shell永远也不会释放CPU,进而其他的应用程序也不能够运行,甚至都不能运行一个第三方的程序来停止或者杀死Shell程序。所以这种场景下,我们基本上得不到真正的multiplexing(CPU在多进程同分时复用)。而这个特性是非常有用的,不论应用程序在执行什么操作,multiplexing都会迫使应用程序时不时的释放CPU,这样其他的应用程序才能运行。
下面给出操作系统中对系统资源进行抽象的一些例子:
-
Unix在进程之间“透明”地切换硬件处理器,根据需要保存和恢复寄存器状态,这样应用程序就不必意识到分时复用的存在。这种透明性允许操作系统共享处理器,即使有些应用程序处于无限循环中。
-
Unix进程使用
exec抽象了内存。当我们在执行exec系统调用的时候,我们会传入一个文件名,而这个文件名对应了一个应用程序的内存镜像。内存镜像里面包括了程序对应的指令,全局的数据。应用程序可以逐渐扩展自己的内存,但是应用程序并没有直接访问物理内存的权限,例如应用程序不能直接访问物理内存的1000-2000这段地址。不能直接访问的原因是,操作系统会提供内存隔离并控制内存,操作系统会在应用程序和硬件资源之间提供一个中间层。 -
Unix进程之间的许多交互形式都是通过文件描述符实现的。文件描述符不仅抽象了许多细节(例如,管道或文件中的数据存储在哪里),而且还以简化交互的方式进行了定义(例如,如果流水线中的一个应用程序失败了,内核会为流水线中的下一个进程生成文件结束信号(EOF))。
-
Files基本上来说抽象了磁盘。应用程序不会直接读写挂在计算机上的磁盘本身,并且在Unix中这也是不被允许的。在Unix中,与存储系统交互的唯一方式就是通过files。Files提供了非常方便的磁盘抽象,你可以对文件命名,读写文件等等。之后,操作系统会决定如何将文件与磁盘中的块对应,确保一个磁盘块只出现在一个文件中,并且确保用户A不能操作用户B的文件。通过files的抽象,可以实现不同用户之间和同一个用户的不同进程之间的文件强隔离。
第一节和Lab1中的各种Unix系统调用接口都是抽象资源的方法(例如Unix应用程序只通过文件系统的open、read、write和close系统调用与存储交互,而不是直接读写磁盘),既为为程序员提供了便利,又提供了很好的隔离性。
User mode, supervisor mode, and system calls
要实现强隔离,操作系统必须保证应用程序不能修改(甚至读取)操作系统的数据结构和指令,以及应用程序不能访问其他进程的内存。通常来说,需要通过硬件来实现这的强隔离性。这里的硬件支持包括了两部分,第一部分是user/kernel mode;第二部分是page table或者虚拟内存(Virtual Memory)。
user/kernel mode
CPU为强隔离提供硬件支持,例如,RISC-V有三种CPU可以执行指令的模式:机器模式(Machine Mode)、用户模式(User Mode)和管理模式(Supervisor Mode)。
- CPU在机器模式下启动,机器模式主要用于配置计算机,在机器模式下执行的指令具有完全特权。Xv6在机器模式下执行很少的几行代码,然后更改为管理模式。大多数场景下,机器模式一般会被忽略。
- 在管理模式下,CPU被允许执行特权指令。例如,启用和禁用中断、读取和写入保存页表地址的寄存器等。如果用户模式下的应用程序试图执行特权指令,那么CPU不会执行该指令,而是切换到管理模式,以便管理模式代码可以终止应用程序,因为它做了它不应该做的事情。
- 应用程序只能执行用户模式的指令(例如,数字相加/减,跳转、分支等),并被称为在用户空间 (user space/mode)中运行;而此时处于管理模式下的软件可以执行特权指令,并被称为在内核空间 (kernel space/mode)中运行,在内核空间(或管理模式)中运行的软件被称为内核。
CPU提供一个特殊的指令(只能由kernel执行的特权指令),将CPU从用户模式切换到管理模式(CPU中一个控制位控制当前处于哪种模式),并在内核指定的入口点进入内核(RISC-V为此提供ECALL指令)。ECALL会跳转到内核中一个特定并由内核控制的位置。每一次应用程序执行ECALL指令,应用程序都会通过这个接入点进入到内核中。举个例子,不论是Shell还是其他的应用程序,当它在用户空间执行fork时,它并不是直接调用操作系统中对应的函数,而是调用ECALL指令,并将fork对应的数字作为参数传给ECALL,之后再通过ECALL跳转到内核。
virtual memory
基本上所有的CPU都支持虚拟内存/page table,而page table将虚拟内存地址与物理内存地址做了对应。每一个进程都会有自己独立的page table,这样的话,每一个进程只能访问出现在自己page table中的物理内存。操作系统会设置page table,使得每一个进程都有不重合的物理内存,这样一个进程就不能访问其他进程的物理内存,因为其他进程的物理内存都不在它的page table中。例如ls程序有了一个内存地址0,echo程序也有了一个内存地址0。但是操作系统会将两个程序的内存地址0映射到不同的物理内存地址,所以ls程序不能访问echo程序的内存,同样echo程序也不能访问ls程序的内存。一个进程甚至都不能随意编造一个内存地址,然后通过这个内存地址来访问其他进程的物理内存。这样就给了我们内存的强隔离性。
Kernel organization
Kernel is Trusted Computing Base!
整个操作系统都驻留在内核中,这样所有系统调用的实现都以管理模式运行。这种组织被称为宏内核(monolithic kernel)。宏内核的一些优点:
- 很方便,因为操作系统设计者不必考虑操作系统的哪一部分不需要完全的硬件特权。
- 操作系统的不同部分更容易合作。例如,一个操作系统可能有一个可以由文件系统和虚拟内存系统共享的数据缓存区。
宏内核的一个缺点是操作系统不同部分之间的接口通常很复杂,因此操作系统开发人员很容易犯错误。在宏内核中,一个错误就可能是致命的,因为管理模式中的错误经常会导致内核失败。如果内核失败,计算机停止工作,因此所有应用程序也会失败。计算机必须重启才能再次使用。
为了降低内核出错的风险,操作系统设计者可以最大限度地减少在管理模式下运行的操作系统代码量,并在用户模式下执行大部分操作系统。这种内核组织被称为微内核(microkernel)。
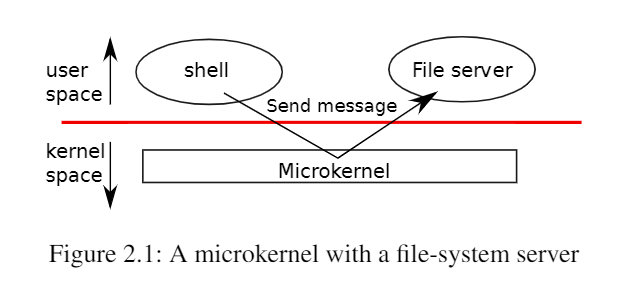
上图中(微内核架构),文件系统作为用户级进程运行。作为进程运行的操作系统服务被称为服务器。为了允许应用程序与文件服务器交互,内核提供了允许从一个用户态进程向另一个用户态进程发送消息的进程间通信机制。例如,如果像shell这样的应用程序想要读取或写入文件,它会向文件服务器发送消息并等待响应。但是这种设计也有相应的问题:假设我们需要让Shell能与文件系统交互,比如Shell调用了exec,必须有种方式可以接入到文件系统中。通常来说,这里工作的方式是:
- Shell会通过内核中的IPC系统发送一条消息,内核会查看这条消息并发现这是给文件系统的消息,之后内核会把消息发送给文件系统。
- 文件系统会完成它的工作之后会向IPC系统发送回一条消息说,这是你的exec系统调用的结果,之后IPC系统再将这条消息发送给Shell。
现在,对于任何文件系统的交互,都需要分别完成2次用户空间<->内核空间的跳转。与宏内核对比,在宏内核中如果一个应用程序需要与文件系统交互,只需要完成1次用户空间<->内核空间的跳转,所以微内核的的跳转是宏内核的两倍。通常微内核的挑战在于性能更差,这里有两个方面需要考虑:
- 在user/kernel mode反复跳转带来的性能损耗。
- 在一个类似宏内核的紧耦合系统,各个组成部分,例如文件系统和虚拟内存系统,可以很容易的共享page cache。而在微内核中,每个部分之间都很好的隔离开了,这种共享更难实现。进而导致更难在微内核中得到更高的性能。
Code: xv6 organization
我们来看下xv6的代码结构,代码主要由三个部分组成。

-
第一个是kernel。我们可以ls kernel的内容,里面包含了基本上所有的内核文件。因为xv6是一个宏内核结构,这里所有的文件会被编译成一个叫做kernel的二进制文件,然后这个二进制文件会被运行在kernle mode中。

-
第二个部分是user。这基本上是运行在user mode的程序。这也是为什么一个目录称为kernel,另一个目录称为user的原因。

- 第三部分叫做mkfs。它会创建一个空的文件镜像,我们会将这个镜像存在磁盘上,这样我们就可以直接使用一个空的文件系统。
内核如何编译
首先,makefile会读取一个c文件,例如proc.c,之后调用gcc编译器,生成一个文件叫做proc.s,这是RISC-V 汇编语言文件;之后再走到汇编解释器,生成proc.o,这是汇编语言的二进制格式。Makefile会为所有内核文件做相同的操作。之后,系统加载器(Loader)会收集所有的.o文件,将它们链接在一起,并生成内核文件。

最后调用QEMU(qemu-system-riscv64指令)。这里本质上是通过C语言来模拟仿真RISC-V处理器。
我们来看传给QEMU的几个参数:
- -kernel:这里传递的是内核文件(kernel目录下的kernel文件),这是将在QEMU中运行的程序文件。
- -m:这里传递的是RISC-V虚拟机将会使用的内存数量
- -smp:这里传递的是虚拟机可以使用的CPU核数
- -drive:传递的是虚拟机使用的磁盘驱动,这里传入的是fs.img文件
这样,XV6系统就在QEMU中启动了。
Process overview
xv6(和其他Unix操作系统一样)中的隔离单位是一个进程,内核用来实现进程的机制包括user/kernel mode标志、地址空间和线程的时间切片。为了帮助加强隔离,进程抽象给程序提供了一种错觉,即它有自己的专用机器(CPU和内存等系统资源)。xv6使用页表(由硬件实现)为每个进程提供自己的地址空间。RISC-V页表将虚拟地址(RISC-V指令操纵的地址)映射为物理地址(CPU芯片发送到主存储器的地址)。
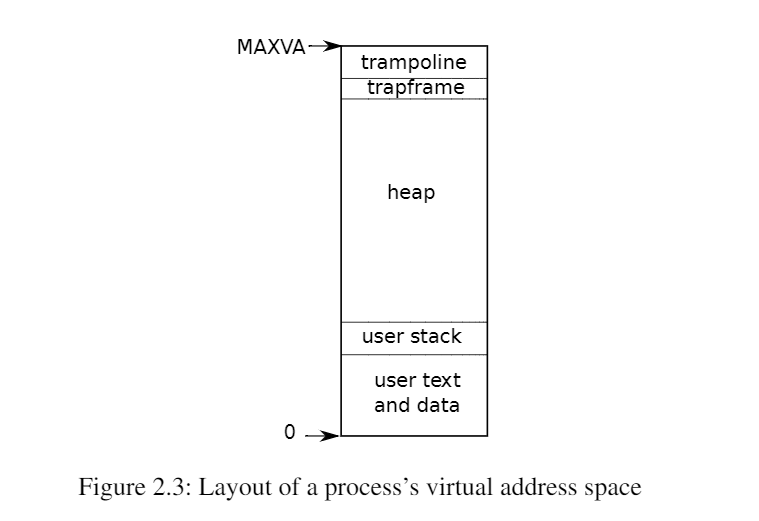
xv6为每个进程维护一个单独的页表,定义了该进程的地址空间。如下图所示,以虚拟内存地址0开始的进程的用户内存地址空间。首先是指令,然后是全局变量,然后是栈区,最后是一个堆区域(用于malloc)以供进程根据需要进行扩展。有许多因素限制了进程地址空间的最大范围: RISC-V上的指针有64位宽;硬件在页表中查找虚拟地址时只使用低39位;xv6只使用这39位中的38位。因此,最大地址是2^38-1=0x3fffffffff,即MAXVA(定义在kernel/riscv.h:348)。在地址空间的顶部,xv6为trampoline(用于在用户和内核之间切换)和映射进程切换到内核的trapframe分别保留了一个页面。
xv6内核为每个进程维护许多状态片段,并将它们聚集到一个proc结构体中。一个进程最重要的内核状态片段是它的页表、内核栈区和运行状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// wait_lock must be held when using this:
struct proc *parent; // Parent process
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
struct trapframe *trapframe; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};
每个进程都由线程来执行进程的指令,一个线程可以挂起并且稍后再恢复。为了透明地在进程之间切换,内核挂起当前运行的线程,并恢复另一个进程的线程。线程的大部分状态(本地变量、函数调用返回地址)存储在线程的栈区上。每个进程有两个栈区:一个用户栈区和一个内核栈区。当进程执行用户指令时,只有它的用户栈在使用,它的内核栈是空的。当进程进入内核(由于系统调用或中断)时,内核代码在进程的内核堆栈上执行;当一个进程在内核中时,它的用户堆栈仍然包含保存的数据,只是不处于活动状态。进程的线程用户栈和内核栈之间交替。内核栈是独立的,因此即使一个进程破坏了它的用户栈,内核依然可以正常运行。
一个进程可以通过执行RISC-V的ecall指令进行系统调用,该指令提升硬件特权级别,并将程序计数器(PC)更改为内核定义的入口点,入口点的代码切换到内核栈,执行实现系统调用的内核指令,当系统调用完成时,内核切换回用户栈,并通过调用sret指令返回用户空间,该指令降低了硬件特权级别,并在系统调用指令刚结束时恢复执行用户指令。
Code: starting xv6 and the first process
OS的启动都类似,Linux 0.11也差不多(可以看Linux内核设计的艺术一书,对这个描述更详细)
当RISC-V计算机上电时,它会初始化自己并运行一个存储在ROM中的引导加载程序。引导加载程序将xv6内核加载到内存中。然后,在机器模式下,中央处理器从_entry (kernel/entry.S:6)开始运行xv6,xv6启动时页式硬件(paging hardware)处于禁用模式:也就是说虚拟地址将直接映射到物理地址。
加载程序将xv6内核加载到物理地址为0x80000000的内存中。它将内核放在0x80000000而不是0x0的原因是地址范围0x0:0x80000000包含I/O设备。entry的指令设置了一个栈区,这样xv6就可以运行C代码。xv6在start. c (kernel/start.c:11)文件中为初始栈stack0声明了空间。由于RISC-V上的栈是向下扩展的,所以entry的代码将栈顶地址stack0+4096加载到栈顶指针寄存器sp中。现在内核有了栈区,_entry便调用C代start(kernel/start.c:21)。
函数start执行一些仅在机器模式下允许的配置,然后切换到管理模式。RISC-V提供指令mret以进入管理模式,该指令最常用于将管理模式切换到机器模式的调用中返回。而start并非从这样的调用返回,而是执行以下操作:它在寄存器mstatus中将先前的运行模式改为管理模式,它通过将main函数的地址写入寄存器mepc将返回地址设为main,它通过向页表寄存器satp写入0来在管理模式下禁用虚拟地址转换,并将所有的中断和异常委托给管理模式。
在进入管理模式之前,start还要执行另一项任务:对时钟芯片进行编程以产生计时器中断。清理完这些“家务”后,start通过调用mret“返回”到管理模式。这将导致程序计数器(PC)的值更改为main(kernel/main.c:11)函数地址。
在main(kernel/main.c:11)初始化几个设备和子系统后,便通过调用userinit (kernel/proc.c:212)创建第一个进程,第一个进程执行一个用RISC-V程序集写的小型程序:initcode. S (user/initcode.S:1),它通过调用exec系统调用重新进入内核。正如我们在第1章中看到的,exec用一个新程序(本例中为 /init)替换当前进程的内存和寄存器。一旦内核完成exec,它就返回/init进程中的用户空间。如果需要,init(user/init.c:15)将创建一个新的控制台设备文件,然后以文件描述符0、1和2打开它。然后它在控制台上启动一个shell。系统就这样启动了。