Introduction
此为MIT 6.S081课程和xv6-Books的学习笔记
页表是操作系统为每个进程提供私有地址空间和内存的机制。页表决定了内存地址的含义,以及物理内存的哪些部分可以访问。它们允许xv6隔离不同进程的地址空间,并将它们复用到单个物理内存上。页表还提供了一层抽象(a level of indirection),这允许xv6执行一些特殊操作:映射相同的内存到不同的地址空间中(a trampoline page),并用一个未映射的页面保护内核和用户栈区。
Paging hardware
RISC-V指令(用户和内核指令)使用的是虚拟地址,而机器的RAM或物理内存是由物理地址索引的。RISC-V页表硬件通过将每个虚拟地址映射到物理地址来为这两种地址建立联系。例如CPU正在执行指令,例如sd $7, (a0)。对于任何一条带有地址的指令,其中的地址应该认为是虚拟内存地址而不是物理地址。假设寄存器a0中是地址0x1000,那么这是一个虚拟内存地址。虚拟内存地址会被转到内存管理单元(MMU,Memory Management Unit),内存管理单元会将虚拟地址翻译成物理地址。之后这个物理地址会被用来索引物理内存,并从物理内存加载,或者向物理内存存储数据。而具体映射规则则通过页表完成。
MMU并不会保存page table,它只会从内存中读取page table,然后完成翻译MMU。

XV6基于Sv39 RISC-V运行,这意味着它只使用64位虚拟地址的低39位(这也是在lab2中在sysinfo调用时传入一个高于39位的地址进行测试),而高25位不使用。
在这种Sv39配置中,RISC-V页表在逻辑上是一个由 $2^{27}$ 个页表条目(Page Table Entries/PTE)组成的数组,每个PTE包含一个44位的物理页码(Physical Page Number/PPN)和一些标志。分页硬件通过使用虚拟地址39位中的前27位索引页表,以找到该虚拟地址对应的一个PTE,然后生成一个56位的物理地址,其前44位来自PTE中的PPN,其后12位来自原始虚拟地址,图3.1显示了这个过程。页表使操作系统能够以 4096 ( $2^{12}$ ) 字节的对齐块的粒度控制虚拟地址到物理地址的转换(即一个页大小为4KB),这样的块称为页(page)。
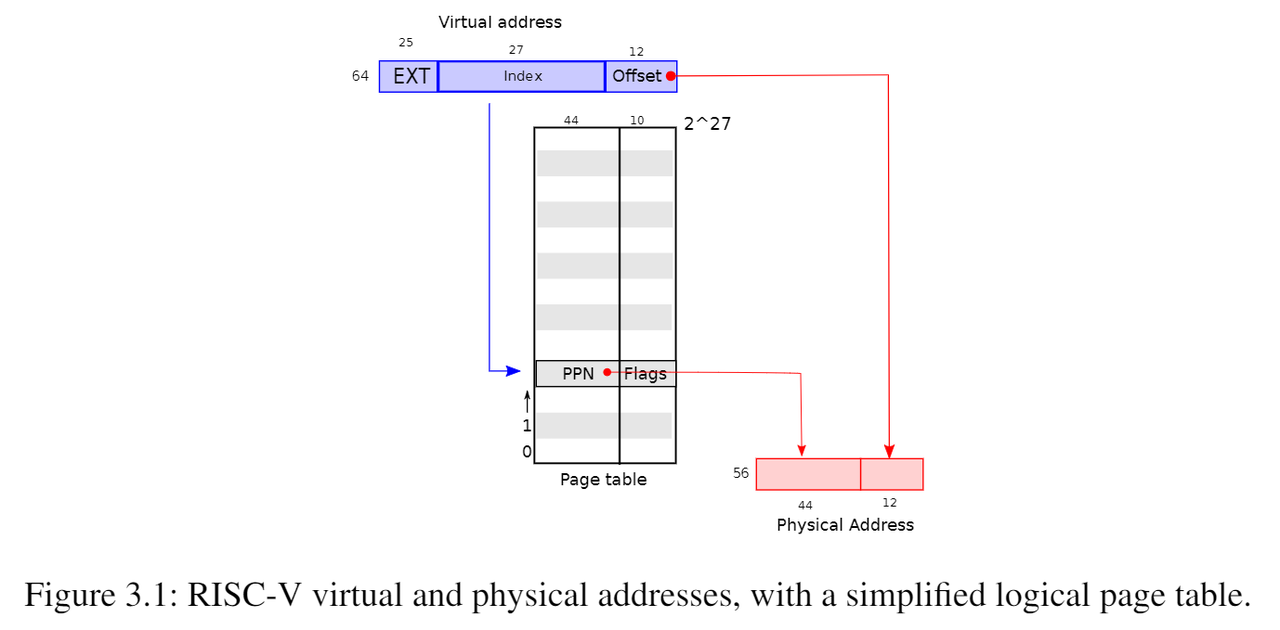
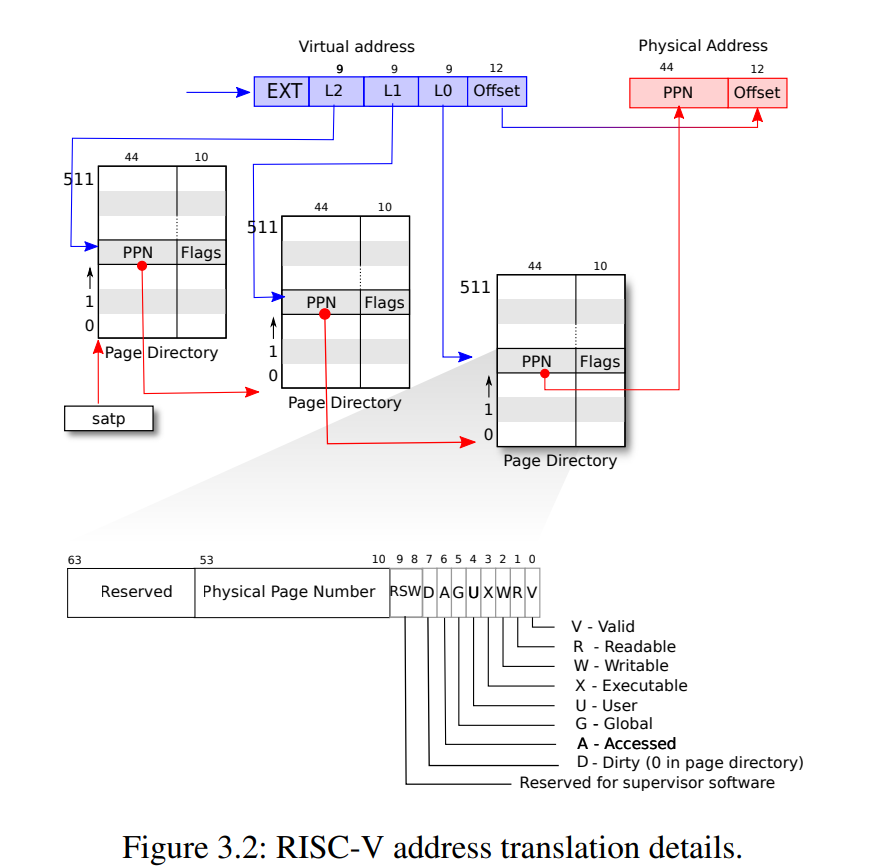
如图3.2所示,实际的转换分三个步骤进行。页表以三级的树型结构存储在物理内存中。该树的根是一个4096字节(4KB,$2^9 * 8$)的页表(page,几乎所有的处理器都使用或者支持4KB的page),其中包含512个($2^9$)PTE,每个PTE中包含该树下一级页表页的物理地址(54位中的前44位,也就是说PPN后面补12个0即(每个页都是4096字节对齐)为下一级页表页的物理地址)。这些页表中的每一个PTE都包含该树最后一级的512个PTE(也就是说每个PTE占8个字节,正如图3.2最下面所描绘的,图3.2上面那个图省略了10位保留位)。分页硬件使用27位中的前9位在根页表页面中选择PTE,中间9位在树的下一级页表页面中选择PTE,最后9位选择最终的PTE。如果转换地址所需的三个PTE中的任何一个不存在,页式硬件就会引发页面故障异常(page-fault exception),并让内核来处理该异常。
三级页表的优点
与图 3.1 的单级设计相比,图 3.2 的三级结构使用了一种更节省内存的方式来记录 PTE。在大范围的虚拟地址没有被映射的常见情况下,三级结构可以忽略整个页面目录。举个例子,如果一个应用程序只使用了一个页面,那么顶级页面目录将只使用条目0,条目 1 到 511 都将被忽略(V位),因此内核不必为这511个条目所对应的中间页面目录分配页面,也就更不必为这 511 个中间页目录分配底层页目录的页。 所以,在这个例子中,三级设计仅使用了三个页面,共占用 $3\times4096$个字节。而一级页表仍需要分配足够的大小容纳整个页面($2^{27}$)。
三级页表的缺点
因为 CPU 在执行转换时会在硬件中遍历三级结构,所以缺点是 CPU 必须从内存中加载三个 PTE 以将虚拟地址转换为物理地址。为了减少从物理内存加载 PTE 的开销,RISC-V CPU 将页表条目缓存在 Translation Look-aside Buffer (TLB) 中。
每个PTE包含标志位,这些标志位告诉分页硬件允许如何使用关联的虚拟地址:
PTE_V指示PTE是否存在:如果它没有被设置,对页面的引用会导致异常(即不允许)。PTE_R控制是否允许指令读取到页面。PTE_W控制是否允许指令写入到页面。PTE_X控制CPU是否可以将页面内容解释为指令并执行它们。PTE_U控制用户模式下的指令是否被允许访问页面;如果没有设置PTE_U,PTE只能在管理模式下使用。
为了告诉MMU使用页表,内核必须将根页表页的物理地址写入到satp寄存器中(satp的作用是存放根页表页在物理内存中的地址)。每个CPU都有自己的satp(或者说每个程序,CPU切换不同的进程时,satp的值会改变),不同的CPU就可以运行不同的进程,一个CPU将使用自己的satp指向的页表转换后续指令生成的所有地址,因此每个进程都有自己的页表描述的私有地址空间。
物理内存和虚拟地址:
-
物理内存是指DRAM中的存储单元。物理内存以一个字节为单位划为地址,称为物理地址。
-
指令只使用虚拟地址,分页硬件将其转换为物理地址,然后将其发送到DRAM硬件来进行读写。
与物理内存和虚拟地址不同,虚拟内存不是物理对象,而是指内核提供的管理物理内存和虚拟地址的抽象和机制的集合。虚拟内存可以比物理内存更大,物理内存也可以比虚拟内存更大。比如说64位电脑的虚拟内存为$2^{64}$字节,而物理内存可以为16G,32G等。但所有程序都必须存在于物理内存中,否则处理器甚至都不能处理程序的指令。因此,操作系统需要使用内存管理单元(MMU)来将虚拟地址映射到物理地址,使得应用程序可以使用所有可用的物理内存。
Translation Lookaside Buffer (TLB)
如果我们回想一下page table的结构,你可以发现,当处理器从内存加载或者存储数据时,基本上都要做3次内存查找,第一次在最高级的page directory,第二次在中间级的page directory,最后一次在最低级的page directory。所以对于一个虚拟内存地址的寻址,需要读三次内存,代价有点高。实际中,几乎所有的处理器都会对于最近使用过的虚拟地址的翻译结果有缓存,这个缓存被称为页表缓存 (Translation Lookside Buffer, TLB)。或者说,TLB就是Page Table Entry的缓存。
当处理器第一次查找一个虚拟地址时,硬件通过3级page table得到最终的PPN,TLB会保存虚拟地址到物理地址的映射关系。这样下一次当你访问同一个虚拟地址时,处理器可以查看TLB,TLB会直接返回物理地址,而不需要通过page table得到结果。当切换进程时,TLB也会刷新。
cache & TLB
Cache 和 TLB 都是现代计算机系统中的存储器层次结构中的组成部分,它们主要的作用是缓存和加速 CPU 访问内存的过程。
Cache 是 CPU 中的一个硬件模块,用于缓存主存储器中的数据,减少 CPU 访问主存的时间,提高 CPU 访问速度。在 CPU 访问内存时,首先会查找 Cache 中是否已经缓存了需要读取的数据,如果已经缓存则直接从 Cache 中读取,否则再从主存中读取数据,并将数据缓存到 Cache 中。Cache 分为多级,常见的有 L1 Cache,L2 Cache,每一级 Cache 的容量越来越大,访问速度也越来越慢。
TLB 是 Translation Lookaside Buffer 的缩写,它是一种特殊的 Cache,用于缓存虚拟地址到物理地址的翻译结果,避免 CPU 每次访问内存时都要进行虚拟地址到物理地址的转换。当 CPU 访问内存时,它首先会将虚拟地址传递给 TLB,如果 TLB 中已经有该虚拟地址到物理地址的翻译结果,则直接取出物理地址,否则将触发缺页异常将虚拟地址传递给 MMU,由 MMU 进行虚拟地址到物理地址的转换,同时将转换结果缓存到 TLB 中,以便下一次访问。
总结说,cache中存储的是内存最近访问的数据,而TLB存储的是虚拟地址到物理地址的翻译结果。
Kernel address space
xv6为每个进程维护一个页表,用以描述每个进程的用户地址空间,外加一个单独描述内核地址空间的页表。内核配置其地址空间的布局,以允许自己以可预测的虚拟地址访问物理内存和各种硬件资源。下图显示了这种布局如何将内核虚拟地址映射到物理地址。
用户地址空间是指一个进程可供其用户程序使用的虚拟地址空间,用于存放进程代码、数据和堆栈等。这个地址空间通常只能被该进程直接访问,并且只能使用自己的内存资源。
内核地址空间是指操作系统内核所使用的虚拟地址空间,用于存放内核代码、堆栈和数据等。这个地址空间专门为操作系统内核服务,进程也可以通过系统调用等机制进行访问。

QEMU模拟了一台计算机,它包括从物理地址0x80000000(KERNBASE,内核虚拟地址空间的起始位置)开始并至少到0x86400000(PHYSTOP,物理内存的上限地址)结束的RAM(物理内存)。QEMU模拟还包括I/O设备,如磁盘接口。QEMU将设备接口作为内存映射控制寄存器暴露给软件,这些寄存器位于物理地址空间0x80000000以下。内核可以通过读取/写入这些特殊的物理地址与设备交互;这种读取和写入与设备硬件而不是RAM通信。
内核使用“直接映射”获取内存和内存映射设备寄存器;也就是说,将资源映射到等于物理地址的虚拟地址。例如,内核本身在虚拟地址空间和物理内存中都位于KERNBASE=0x80000000。直接映射简化了读取或写入物理内存的内核代码。例如,当fork为子进程分配用户内存时,分配器返回该内存的物理地址;fork在将父进程的用户内存复制到子进程时直接将该地址用作虚拟地址。
关于上述fork例子的理解:
在xv6中,每个进程拥有自己独立的页表,用于描述该进程的用户地址空间。当一个新的子进程被创建时,它需要拥有自己的用户地址空间(页表)。这时,
fork函数会通过分配器(allocator)来请求系统为子进程分配一块物理空间作为其用户地址空间,并返回该空间的物理地址。接下来,
fork函数会将父进程的用户地址空间复制到子进程的用户地址空间中。注意,这里所说的复制是指将数据从父进程的用户空间复制到子进程的用户空间(父进程页的内容复制给子进程页),而不是将整个的页表完全复制。为了使父子进程之间不互相干扰,在复制过程中需要保证两个进程使用的虚拟地址和物理地址映射是不同的。因此,在复制父进程的用户地址空间时,fork函数直接使用刚才分配的物理地址作为子进程的虚拟地址。这样,子进程就有了自己独立的用户地址空间,并且可以开始运行了。
有几个内核虚拟地址不是直接映射:
- 蹦床页面(trampoline page)。主要用于在切换到内核模式时保护用户态寄存器的值,它映射在虚拟地址空间的顶部;用户页表具有相同的映射。我们在这里看到了一个有趣的页表用例;一个物理页面(持有蹦床代码)在内核的虚拟地址空间中映射了两次:一次在虚拟地址空间的顶部,一次直接映射(指跳转至内核运行时,内核代码和数据被直接映射到了子进程的用户空间)。
- 内核栈页面。每个进程都有自己的内核栈,它将映射到偏高一些的地址,这样xv6在它之下就可以留下一个未映射的保护页(guard page)。保护页的PTE是无效的(也就是说
PTE_V没有设置),所以如果内核溢出内核栈就会引发一个异常,内核触发panic。如果没有保护页,栈溢出将会覆盖其他内核内存,引发错误操作。恐慌崩溃(panic crash)是更可取的方案。(注:Guard page不会浪费物理内存,它只是占据了虚拟地址空间的一段靠后的地址,但并不映射到物理地址空间。)
Code: creating an address space
大多数用于操作地址空间和页表的xv6代码都写在 vm.c\ (kernel/vm.c:1) 中。
- vm.c的核心数据结构是
pagetable_t,它实际上是指向RISC-V根页表页的指针;一个pagetable_t可以是内核页表,也可以是一个进程页表。 - 最核心的函数是
walk和mappages,前者为虚拟地址找到PTE,后者为新映射装载PTE。 - 名称以
kvm开头的函数操作内核页表。以uvm开头的函数操作用户页表。其他函数用于二者。 copyout和copyin复制数据到用户虚拟地址或从用户虚拟地址复制数据,这些虚拟地址作为系统调用参数提供; 由于它们需要显式地翻译这些地址,以便找到相应的物理内存,故将它们写在vm.c中。
在启动序列的前期(xv6启用RISC-V的分页之前),main 调用 kvminit (kernel/vm.c:54) 以使用kvmmake (kernel/vm.c:20) 创建内核的页表,此时地址直接引用物理内存。 kvmmake 首先分配一个物理内存页来保存根页表页。然后它调用kvmmap来装载内核需要的转换。转换包括内核的指令和数据、物理内存的上限到 PHYSTOP,并包括实际上是设备的内存。 Proc_mapstacks (kernel/proc.c:33) 为每个进程分配一个内核堆栈。它调用 kvmmap 将每个堆栈映射到由 KSTACK 生成的虚拟地址,从而为无效的堆栈保护页面留出空间。
kvmmap(kernel/vm.c:127)调用mappages(kernel/vm.c:138),mappages将范围虚拟地址到同等范围物理地址的映射装载到一个页表中。它以页面大小为间隔,为范围内的每个虚拟地址单独执行此操作。对于要映射的每个虚拟地址,mappages调用walk来查找该地址的PTE地址。然后,它初始化PTE以保存相关的物理页号、所需权限(PTE_W、PTE_X和/或PTE_R)以及用于标记PTE有效的PTE_V(kernel/vm.c:153)。
在查找PTE中的虚拟地址(参见图3.2)时,walk(kernel/vm.c:72)模仿RISC-V分页硬件。walk一次从3级页表中获取9个比特位。它使用上一级的9位虚拟地址来查找下一级页表或最终页面的PTE (kernel/vm.c:78)。如果PTE无效,则所需的页面还没有分配;如果设置了alloc参数,walk就会分配一个新的页表页面,并将其物理地址放在PTE中。它返回树中最低一级的PTE地址(kernel/vm.c:88)。
上面的代码依赖于直接映射到内核虚拟地址空间中的物理内存。例如,当walk降低页表的级别时,它从PTE (kernel/vm.c:80)中提取下一级页表的(物理)地址,然后使用该地址作为虚拟地址来获取下一级的PTE (kernel/vm.c:78)。
main调用kvminithart (kernel/vm.c:53)来安装内核页表。它将根页表页的物理地址写入寄存器satp。之后,CPU将使用内核页表转换地址。由于内核使用标识映射,下一条指令的当前虚拟地址将映射到正确的物理内存地址。
main中调用的procinit (kernel/proc.c:26)为每个进程分配一个内核栈。它将每个栈映射到KSTACK生成的虚拟地址,这为无效的栈保护页面留下了空间。kvmmap将映射的PTE添加到内核页表中,对kvminithart的调用将内核页表重新加载到satp中,以便硬件知道新的PTE。
每个RISC-V CPU都将页表条目缓存在转译后备缓冲器(快表/TLB)中,当xv6更改页表时,它必须告诉CPU使相应的缓存TLB条目无效。如果没有这么做,那么在某个时候TLB可能会使用旧的缓存映射,指向一个在此期间已分配给另一个进程的物理页面,这样会导致一个进程可能能够在其他进程的内存上涂鸦。RISC-V有一个指令sfence.vma,用于刷新当前CPU的TLB。xv6在重新加载satp寄存器后,在kvminithart中执行sfence.vma,并在返回用户空间之前在用于切换至一个用户页表的trampoline代码中执行sfence.vma (kernel/trampoline.S3:79)。
Physical memory allocation
内核必须在运行时为页表、用户内存、内核栈和管道缓冲区分配和释放物理内存。xv6使用内核末尾到PHYSTOP之间的物理内存(即上一个图中的Free memory)进行运行时分配。它一次分配和释放整个4096字节的页面(以page为单位),它使用链表的数据结构(lab2中的kvm.freelist)将空闲页面记录下来,分配时需要从链表中删除页面;释放时需要将释放的页面添加到链表中。
Code: Physical memory allocator
这一部分建议看教学视频,更好理解
分配器 (allocator) 位于kalloc.c(kernel/kalloc.c:1)中,分配器的数据结构是可供分配的物理内存页的空闲列表,每个空闲页的列表元素是一个struct run(kernel/kalloc.c:17)。分配器从哪里获得内存来填充该数据结构呢?它将每个空闲页的run结构存储在空闲页本身,因为在那里没有存储其他东西。空闲列表受到自旋锁(spin lock)的保护(kernel/kalloc.c:21-24)。列表和锁被封装在一个结构体中,以明确锁在结构体中保护的字段。现在,忽略锁以及对acquire和release的调用;第6章将详细查看有关锁的细节。
对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起申请者睡眠,如果自旋锁已经被别的执行单元保持,申请者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,”自旋”一词就是因此而得名。
自旋锁比较适用于锁使用者保持锁时间比较短的情况。正是由于自旋锁使用者一般保持锁时间非常短,因此选择自旋而不是睡眠是非常必要的,自旋锁的效率远高于互斥锁。
main函数调用kinit(kernel/kalloc.c:27)来初始化分配器。kinit初始化空闲列表以保存从内核结束到PHYSTOP之间的每一页。xv6应该通过解析硬件提供的配置信息来确定有多少物理内存可用。然而,xv6假设机器有128兆字节的RAM。kinit调用freerange将内存添加到空闲列表中,在freerange中每页都会调用kfree。PTE只能引用在4096字节边界上对齐的物理地址(是4096的倍数),所以freerange使用PGROUNDUP来确保它只释放对齐的物理地址。分配器开始时没有内存;这些对kfree的调用给了它一些管理空间。
分配器有时将地址视为整数,以便对其执行算术运算(例如,在freerange中遍历所有页面),有时将地址用作读写内存的指针(例如,操纵存储在每个页面中的run结构);这种地址的双重用途是分配器代码充满C类型转换的主要原因。另一个原因是释放和分配从本质上改变了内存的类型。
函数kfree (kernel/kalloc.c:47)首先将内存中的每一个字节设置为1。这将导致使用释放后的内存的代码(使用“悬空引用”)读取到垃圾信息而不是旧的有效内容,从而希望这样的代码更快崩溃。然后kfree将页面前置(头插法)到空闲列表中:它将pa转换为一个指向struct run的指针r,在r->next中记录空闲列表的旧开始,并将空闲列表设置为等于r。
kalloc删除并返回空闲列表中的第一个元素。
Process address space
每个进程都有一个单独的页表,当xv6在进程之间切换时,也会更改页表。如图2.3所示,一个进程的用户内存从虚拟地址零开始,可以增长到MAXVA (kernel/riscv.h:348),原则上允许一个进程内存寻址空间为256G。
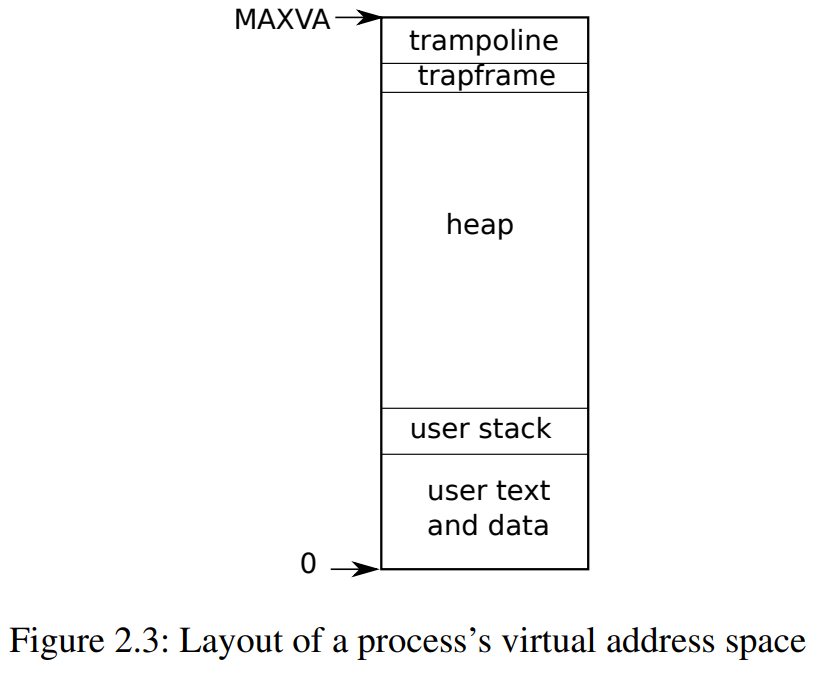
当进程向xv6请求更多的用户内存时,xv6首先使用kalloc来分配物理页面,然后将PTE(设置了PTE_W、PTE_X、PTE_R、PTE_U和PTE_V标志)添加到进程的页表中,指向新的物理页面。大多数进程不使用整个用户地址空间,因此xv6在未使用的PTE中留空PTE_V。
我们再次总结一下进程内存空间和页表:
- 首先,不同进程的页表将用户地址转换为物理内存的不同页面,这样每个进程都拥有私有内存。
- 第二,每个进程看到的自己的内存空间都是以0地址起始的连续虚拟地址,而进程的物理内存可以是非连续的。
- 第三,内核在用户地址空间的顶部映射一个带有蹦床(trampoline)代码的页面,这样在所有地址空间都可以看到一个单独的物理内存页面(trampoline)。
图3.4更详细地显示了xv6中执行态进程的用户内存布局。栈是单独一个页面,显示的是由exec创建后的初始内容。包含命令行参数的字符串以及指向它们的指针数组位于栈的最顶部。再往下是允许程序在main处开始启动的值(即main的地址、argc、argv),这些值产生的效果就像刚刚调用了main(argc, argv)一样。
这一部分可以看OS Security Lab 缓冲区溢出中对c程序运行时栈帧的讲解。
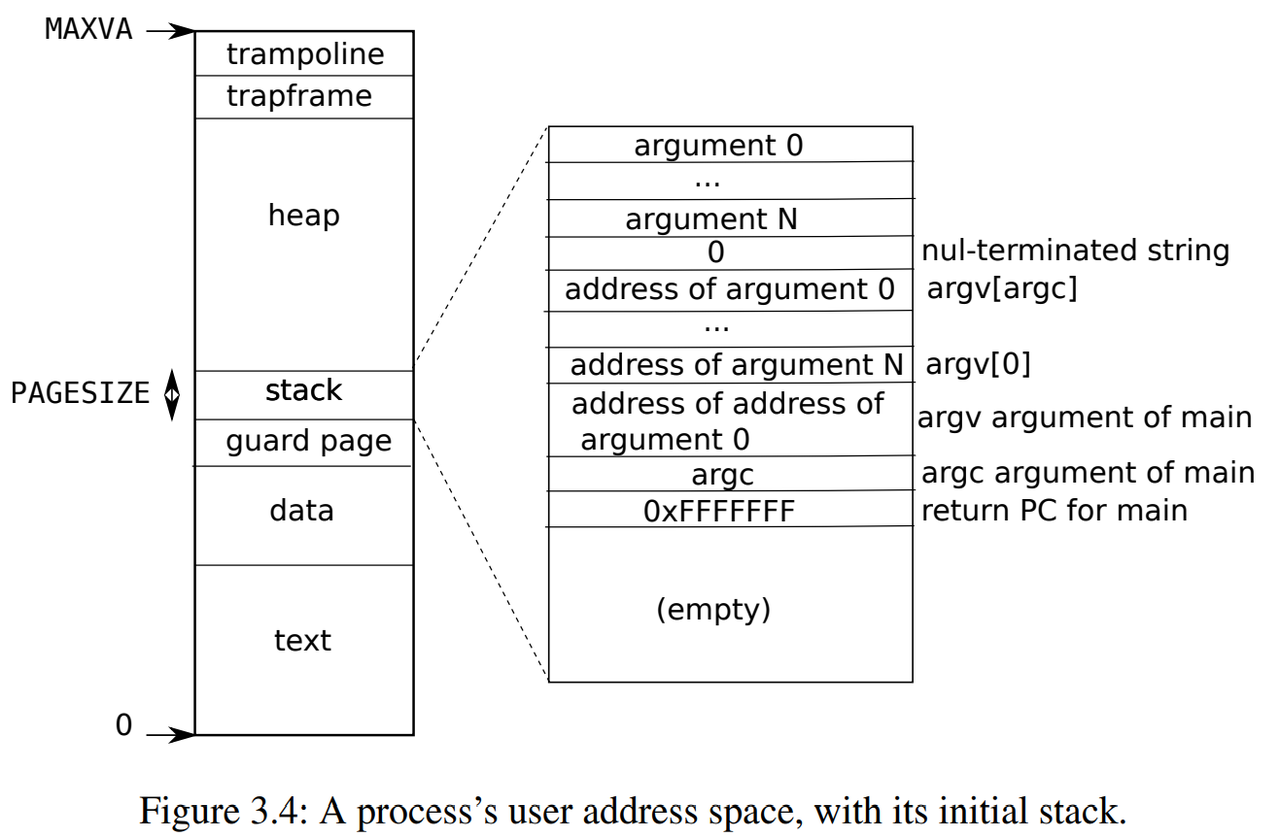
为了检测用户栈是否溢出了所分配栈内存,xv6在栈正下方放置了一个无效的保护页(guard page)。如果用户栈溢出并且进程试图使用栈下方的地址(栈由高地址向低地址,向下增长),那么由于映射无效(PTE_V为0)硬件将生成一个页面故障异常。当用户栈溢出时,实际的操作系统可能会自动为其分配更多内存。
关于栈和堆的增长方向:
栈和堆之所以增长方向相反,是由于它们的内存使用习惯不同。栈主要用于存储程序在当前执行时需要的数据以及函数调用和返回相关的信息,而这些数据通常具有临时性和局部性,即它们只在当前函数的作用域中存在,一旦函数返回,这些数据就被释放了。因此,为了更好地利用内存空间,栈会从高地址向低地址增长,使得新的数据能够压入到已经分配的内存区域中,达到更高的内存利用率。
相反,堆则用于动态管理程序运行期间申请和释放的内存,这些内存通常具有较长的生命周期并且需要在程序的不同作用域中访问。由于堆在使用时大小不确定,因此它会从低地址向高地址增长,使得越来越多的内存能够被动态地扩展。
总之,栈和堆的增长方向是根据其使用习惯内存管理策略来设计的,并没有绝对正确或错误的选择。
Code: sbrk
sbrk是一个用于进程减少或增长其内存的系统调用。这个系统调用由函数growproc实现(kernel/proc.c:239)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// kernel/sysproc.c
uint64
sys_sbrk(void)
{
int addr;
int n;
if(argint(0, &n) < 0) // 将sbrk()的参数从p->trapframe->a0中取出赋给n
return -1;
addr = myproc()->sz;
if(growproc(n) < 0)
return -1;
return addr; // 返回新内存地址的初始位置(其实没变),但是如果sbrk失败会返回-1
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// kernel/proc.c
// Grow or shrink user memory by n bytes.
// Return 0 on success, -1 on failure.
int
growproc(int n)
{
uint sz;
struct proc *p = myproc();
sz = p->sz; // Size of process memory (bytes)
if(n > 0){
if((sz = uvmalloc(p->pagetable, sz, sz + n)) == 0) {
return -1;
}
} else if(n < 0){
sz = uvmdealloc(p->pagetable, sz, sz + n);
}
p->sz = sz;
return 0;
}
growproc根据n是正的还是负的调用uvmalloc或uvmdealloc。
-
uvmalloc(kernel/vm.c:229)用kalloc分配物理内存,并用mappages将PTE添加到用户页表中。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
// kernel/vm.c // Allocate PTEs and physical memory to grow process from oldsz to // newsz, which need not be page aligned. Returns new size or 0 on error. uint64 uvmalloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz) { char *mem; uint64 a; // 虽然在growproc中只有n>0,也就是说newsz>oldsz的情况下才会调用uvmalloc函数, // 也就是说if中的条件判断在此条件下永远为false,似乎可以去掉这行代码;但uvmalloc函数 // 还可能在其他情况下被调用,比如说需要重新映射一块已经存在的用户地址空间、申请内存失败时 // 需要收回之前分配的物理页等等。因此,if判断语句存在的意义是保证了如果所请求的大小nnewsz // 小于或等于oldsz,则uvmalloc不会做任何处理直接返回原来的地址,避免浪费且不必要地重新分 // 配内存。这个优化可以提高系统的性能和效率。 if(newsz < oldsz) return oldsz; // #define PGROUNDUP(sz) (((sz)+PGSIZE-1) & ~(PGSIZE-1)) // PGROUNDUP是一个宏函数。它的作用是将一个给定的大小(sz)上取整到下一个页面边界的大小,并返回这个值。从而确保内存块从页面的边界开始,也就是页对齐。 // 这个位操作得系统学习一下!!!现在有点难理解怎么想到的,太骚了。 oldsz = PGROUNDUP(oldsz); for(a = oldsz; a < newsz; a += PGSIZE){ mem = kalloc(); // 出现没有空闲内存的情况,此时直接调用uvmdealloc恢复至初始时。 if(mem == 0){ uvmdealloc(pagetable, a, oldsz); return 0; } memset(mem, 0, PGSIZE); // note: 这里a为虚拟地址,mem为物理地址 // kernel/riscv.h // #define PTE_V (1L << 0) // valid // #define PTE_R (1L << 1) // #define PTE_W (1L << 2) // #define PTE_X (1L << 3) // #define PTE_U (1L << 4) // 1 -> user can access // 00100 | 01000 | 00010 | 10000 = 11110 if(mappages(pagetable, a, PGSIZE, (uint64)mem, PTE_W|PTE_X|PTE_R|PTE_U) != 0){ // 页映射失败就释放内存 kfree(mem); uvmdealloc(pagetable, a, oldsz); return 0; } } return newsz; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
// kernel/kalloc.c // Allocate one 4096-byte page of physical memory. // Returns a pointer that the kernel can use. // Returns 0 if the memory cannot be allocated. void * kalloc(void) { struct run *r; acquire(&kmem.lock); r = kmem.freelist; // r不为Null即表示有空闲内存 if(r) kmem.freelist = r->next; // 更新空闲内存链表 release(&kmem.lock); if(r) memset((char*)r, 5, PGSIZE); // fill with junk return (void*)r; } // (char*)r 和 (void*)r 都是强制类型转换的表达式,将指针 r 转换为不同的指针类型。 // (char*)r 将指针 r 转换为指向字符类型的指针,即将地址解释为字节序列,并可以对这些字节进 // 行读写操作。这种类型转换通常用于处理二进制数据或字符串。 // (void*)r 将指针 r 转换为通用指针类型,即不指定具体的数据类型,只是将地址作为整数值来处 // 理。这种类型转换通常用于指针赋值、传递参数等情况中,当不知道指针所指向的具体类型时可以使用 // 通用指针。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
// kernel/vm.c // Create PTEs for virtual addresses starting at va that refer to // physical addresses starting at pa. va and size might not // be page-aligned. Returns 0 on success, -1 if walk() couldn't // allocate a needed page-table page. int mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm) { uint64 a, last; pte_t *pte; a = PGROUNDDOWN(va); last = PGROUNDDOWN(va + size - 1); for(;;){ if((pte = walk(pagetable, a, 1)) == 0) return -1; if(*pte & PTE_V) panic("remap"); *pte = PA2PTE(pa) | perm | PTE_V; if(a == last) break; a += PGSIZE; pa += PGSIZE; } return 0; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55
// kernel/vm.c // Return the address of the PTE in page table pagetable // that corresponds to virtual address va. If alloc!=0, // create any required page-table pages. // // The risc-v Sv39 scheme has three levels of page-table // pages. A page-table page contains 512 64-bit PTEs. // A 64-bit virtual address is split into five fields: // 39..63 -- must be zero. // 30..38 -- 9 bits of level-2 index. // 21..29 -- 9 bits of level-1 index. // 12..20 -- 9 bits of level-0 index. // 0..11 -- 12 bits of byte offset within the page. pte_t * walk(pagetable_t pagetable, uint64 va, int alloc) { if(va >= MAXVA) panic("walk"); for(int level = 2; level > 0; level--) { // kernel/riscv.h // #define PGSHIFT 12 // bits of offset within a page // extract the three 9-bit page table indices from a virtual address. // #define PXMASK 0x1FF // 9 bits // #define PXSHIFT(level) (PGSHIFT+(9*(level))) // #define PX(level, va) ((((uint64) (va)) >> PXSHIFT(level)) & PXMASK) // 这段代码实现了从虚拟地址中提取三个9位页表索引的功能。其中: // PXMASK表示9个二进制位都为1,即0x1FF。 // PXSHIFT(level)表示第level级页表偏移量,它的值等于PGSHIFT + 9 * level,其中 // PGSHIFT是一个用于对齐页面的常数,在xv6中被定义为12,因此表示每个页面大小为2^12字 // 节,在二进制中即是1<<12。 // PX(level, va)则通过右移虚拟地址va相应的位数,再与PXMASK按位与运算,从而获得对应的 // 第level级页表索引。 // 以第一级页表为例,一个32位虚拟地址0x0000abcd会先右移12位(即PGSHIFT),变成 // 0xabc,然后再右移9位(即PXSHIFT(1)),变成0x5,最后与PXMASK按位与也就是不变,即 // 还是0x5。因此,这个虚拟地址的第一级页表索引为5。类似地,可以提取出第二级和第三级页表 // 索引。 pte_t *pte = &pagetable[PX(level, va)]; // 如果PTE_V为1则获取PTE物理地址 if(*pte & PTE_V) { pagetable = (pagetable_t)PTE2PA(*pte); // #define PTE2PA(pte) (((pte) >> 10) << 12) } else { // PTE_V不为1即缺页,进行分配页 if(!alloc || (pagetable = (pde_t*)kalloc()) == 0) return 0; memset(pagetable, 0, PGSIZE); *pte = PA2PTE(pagetable) | PTE_V; } } return &pagetable[PX(0, va)]; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
// kernel/kalloc.c // Free the page of physical memory pointed at by v, // which normally should have been returned by a // call to kalloc(). (The exception is when // initializing the allocator; see kinit above.) void kfree(void *pa) { struct run *r; // pa是否为PGSIZE的倍数,是否在代码区,是否小于等于物理内存的末尾 if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP) panic("kfree"); // Fill with junk to catch dangling refs. memset(pa, 1, PGSIZE); r = (struct run*)pa; // 链表的删除 acquire(&kmem.lock); r->next = kmem.freelist; kmem.freelist = r; release(&kmem.lock); }
-
uvmdealloc调用uvmunmap(kernel/vm.c:174),uvmunmap使用walk来查找对应的PTE,并使用kfree来释放PTE引用的物理内存。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
// kernel/vm.c // Deallocate user pages to bring the process size from oldsz to // newsz. oldsz and newsz need not be page-aligned, nor does newsz // need to be less than oldsz. oldsz can be larger than the actual // process size. Returns the new process size. uint64 uvmdealloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz) { if(newsz >= oldsz) return oldsz; if(PGROUNDUP(newsz) < PGROUNDUP(oldsz)){ // 计算oldsz和newsz之间的页表数 int npages = (PGROUNDUP(oldsz) - PGROUNDUP(newsz)) / PGSIZE; uvmunmap(pagetable, PGROUNDUP(newsz), npages, 1); } return newsz; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
// kernel/vm.c // Remove npages of mappings starting from va. va must be // page-aligned. The mappings must exist. // Optionally free the physical memory. void uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free) { uint64 a; pte_t *pte; // 检查,以页为单位 if((va % PGSIZE) != 0) panic("uvmunmap: not aligned"); for(a = va; a < va + npages*PGSIZE; a += PGSIZE){ if((pte = walk(pagetable, a, 0)) == 0) panic("uvmunmap: walk"); if((*pte & PTE_V) == 0) panic("uvmunmap: not mapped"); // #define PTE_FLAGS(pte) ((pte) & 0x3FF) // 获取标志位 if(PTE_FLAGS(*pte) == PTE_V) panic("uvmunmap: not a leaf"); // 非叶子节点(多级页表每个节点是叶子节点或者 // 非叶子节点(存储的不是一个物理内存地址,而是指向下一级页表的指针。)) if(do_free){ uint64 pa = PTE2PA(*pte); // 释放物理内存 kfree((void*)pa); } *pte = 0; } }
xv6使用进程的页表,不仅是告诉硬件如何映射用户虚拟地址,也是明晰哪一个物理页面已经被分配给该进程的唯一记录。这就是为什么释放用户内存(在uvmunmap中)需要检查用户页表的原因。
Code: exec
exec是创建地址空间的用户部分的系统调用,它使用一个存储在文件系统中的文件初始化地址空间的用户部分。exec(kernel/exec.c:13)使用namei (kernel/exec.c:26)打开指定的二进制path。然后,它读取ELF头。xv6中的应用程序为ELF文件格式(kernel/elf.h)。ELF二进制文件由ELF头 (struct elfhdr(kernel/elf.h:6)),后面一系列的程序节头 (section headers,struct proghdr(kernel/elf.h:25))组成。每个proghdr描述程序中必须加载到内存中的一节(section),xv6程序只有一个程序节头,但是其他系统对于指令和数据部分可能各有单独的节。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
// kernel/elf.h
// Format of an ELF executable file
#define ELF_MAGIC 0x464C457FU // "\x7FELF" in little endian
// File header
struct elfhdr {
uint magic; // must equal ELF_MAGIC
uchar elf[12];
ushort type;
ushort machine;
uint version;
uint64 entry;
uint64 phoff;
uint64 shoff;
uint flags;
ushort ehsize;
ushort phentsize;
ushort phnum;
ushort shentsize;
ushort shnum;
ushort shstrndx;
};
// Program section header
struct proghdr {
uint32 type;
uint32 flags;
uint64 off;
uint64 vaddr;
uint64 paddr;
uint64 filesz;
uint64 memsz;
uint64 align;
};
// Values for Proghdr type
#define ELF_PROG_LOAD 1
// Flag bits for Proghdr flags
#define ELF_PROG_FLAG_EXEC 1
#define ELF_PROG_FLAG_WRITE 2
#define ELF_PROG_FLAG_READ 4
第一步是快速检查文件可能包含ELF二进制的文件。ELF二进制文件以四个字节的“magic number” 0x7F、“E”、“L”、“F”或ELF_MAGIC开始(kernel/elf.h:3)。如果ELF头有正确的magic number,exec假设二进制文件格式正确。exec使用proc_pagetable (kernel/exec.c:38)分配一个没有用户映射的新页表,使用uvmalloc (kernel/exec.c:52)为每个ELF段分配内存,并使用loadseg (kernel/exec.c:10)将每个段加载到内存中。loadseg使用walkaddr找到分配内存的物理地址,在该地址写入ELF段的每一页,并使用readi从文件中读取。
使用exec创建的第一个用户程序/init的section header如下:
1
2
3
4
5
6
7
8
9
# objdump -p _init
user/_init: file format elf64-littleriscv
Program Header:
LOAD off 0x00000000000000b0 vaddr 0x0000000000000000
paddr 0x0000000000000000 align 2**3
filesz 0x0000000000000840 memsz 0x0000000000000858 flags rwx
STACK off 0x0000000000000000 vaddr 0x0000000000000000
paddr 0x0000000000000000 align 2**4
filesz 0x0000000000000000 memsz 0x0000000000000000 flags rw-
程序节头的filesz可能小于memsz,这表明它们之间的间隙应该用零来填充(对于C全局变量),而不是从文件中读取。对于/init,filesz是2112字节,memsz是2136字节,因此uvmalloc分配了足够的物理内存来保存2136字节,但只从文件/init中读取2112字节。
现在exec分配并初始化用户栈。它只分配一个栈页面。exec一次将参数中的一个字符串复制到栈顶,并在ustack中记录指向它们的指针。它在传递给main的argv列表的末尾放置一个空指针。ustack中的前三个条目是伪返回程序计数器(fake return program counter)、argc和argv指针。
exec在栈页面的正下方放置了一个不可访问的页面,这样试图使用超过一个页面的程序就会出错。这个不可访问的页面还允许exec处理过大的参数;在这种情况下,被exec用来将参数复制到栈的函数copyout(kernel/vm.c:355) 将会注意到目标页面不可访问,并返回-1。
在准备新内存映像的过程中,如果exec检测到像无效程序段这样的错误,它会跳到标签bad,释放新映像,并返回-1。exec必须等待系统调用会成功后再释放旧映像:因为如果旧映像消失了,系统调用将无法返回-1。exec中唯一的错误情况发生在映像的创建过程中。一旦映像完成,exec就可以提交到新的页表(kernel/exec.c:113)并释放旧的页表(kernel/exec.c:117)。
exec将ELF文件中的字节加载到ELF文件指定地址的内存中。用户或进程可以将他们想要的任何地址放入ELF文件中。因此exec是有风险的,因为ELF文件中的地址可能会意外或故意的引用内核。对一个设计拙劣的内核来说,后果可能是一次崩溃,甚至是内核的隔离机制被恶意破坏(即安全漏洞)。xv6执行许多检查来避免这些风险。例如,if(ph.vaddr + ph.memsz < ph.vaddr)检查总和是否溢出64位整数,危险在于用户可能会构造一个ELF二进制文件,其中的ph.vaddr指向用户选择的地址,而ph.memsz足够大,使总和溢出到0x1000,这看起来像是一个有效的值。在xv6的旧版本中,用户地址空间也包含内核(但在用户模式下不可读写),用户可以选择一个与内核内存相对应的地址,从而将ELF二进制文件中的数据复制到内核中。在xv6的RISC-V版本中,这是不可能的,因为内核有自己独立的页表;loadseg加载到进程的页表中,而不是内核的页表中。
内核开发人员很容易省略关键的检查,而现实世界中的内核有很长一段丢失检查的历史,用户程序可以利用这些检查的缺失来获得内核特权。xv6可能没有完成验证提供给内核的用户级数据的全部工作,恶意用户程序可以利用这些数据来绕过xv6的隔离。