Introduction
此为MIT 6.S081课程和xv6-Books的学习笔记
在多处理器硬件和多线程环境下,多个指令流可能会交错执行,导致并发访问数据。为了保证数据的正确性,内核设计者需要使用并发控制技术来控制并发访问,而锁是一种广泛使用的并发控制技术。锁提供了互斥,确保一次只有一个CPU可以持有锁。如果程序员将每个共享数据项关联一个锁,并且代码在使用一个数据项时总是持有相关联的锁,那么该项一次将只被一个CPU使用。虽然锁是一种易于理解的并发控制机制,但锁的缺点是它们会扼杀性能,因为它们会串行化并发操作。
Race conditions
一个为什么需要锁的小例子
假设两个进程在两个不同的CPU上调用wait,wait释放了子进程的内存。因此,在每个CPU上,内核将调用kfree(将一个内存页面push到空闲列表上)来释放子进程的页面。为了获得最佳性能,我们可能希望两个父进程的kfree可以并行执行,而不必等待另一个进程,但是考虑到xv6的kfree实现,这将导致错误。
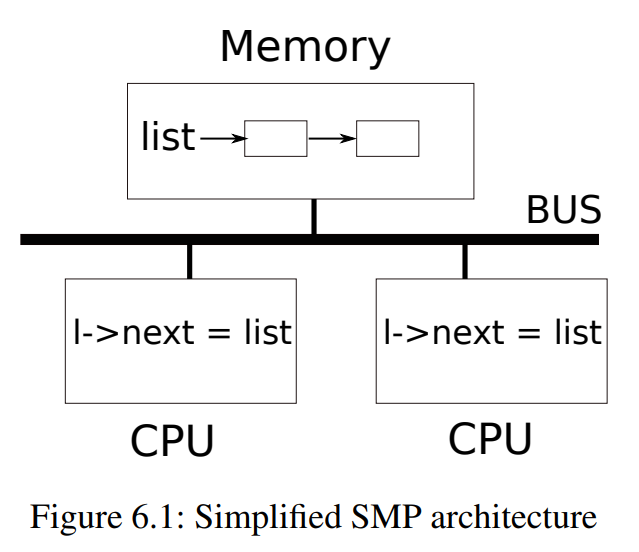
上图更详细地说明了上述设定:链表位于两个CPU共享的内存中,这两个CPU使用load和store指令操作链表(实际上每个处理器都有cache,但从概念上讲,多处理器系统的行为就像所有CPU共享一块单独的内存一样)。如果没有并发请求,您可能以如下方式实现列表push操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
struct element {
int data;
struct element *next;
};
struct element *list = 0;
void push(int data){
struct element *l;
l = malloc(sizeof *l);
l->data = data;
l->next = list;
list = l;
}
但是如果多个副本并发执行,代码就会出错,例如图6.1的情况。两个CPU都可能在执行第14行之前执行第13行,这会导致不正确的结果:会有两个类型为element的列表元素使用next指针设置为list的最前的一个值;而当两次执行位于第14行的对list的赋值时,第二次赋值将覆盖第一次赋值,这会导致第一次赋值中涉及的element元素将丢失,也就是丢失了一个空闲页。第14行丢失的更新是竞态条件(race condition)的一个例子,竞态条件是指多个进程读写某些共享数据(至少有一个访问是写入)的情况。竞争通常包含bug,要么丢失更新(如果访问是写入的),要么读取未完成更新的数据结构,竞争的结果取决于进程在处理器运行的确切时机以及内存系统如何排序它们的内存操作,这可能会使竞争引起的错误难以复现和调试。
避免竞争的通常方法是使用锁。锁确保互斥,这样一次只有一个CPU可以执行push中敏感的代码行,这使得上述情况不可能发生。上面代码的正确上锁版本如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
struct element {
int data;
struct element *next;
};
struct element *list = 0;
struct lock listlock;
void push(int data){
struct element *l;
l = malloc(sizeof *l);
l->data = data;
// acquire lock
acquire(&listlock);
/* 临界区域 */
l->next = list;
list = l;
/* */
release(&listlock);
// release lock
}
当使用锁保护数据时,实际上是保护适用于数据的某些不变量集合,不变量是跨操作维护的数据结构的属性。操作可能暂时违反不变量,但必须在完成之前重新建立它们。例如,在链表的例子中,不变量是list指向列表中的第一个元素,以及每个元素的next字段指向下一个元素。push的实现暂时违反了这个不变量:在第17行,l->next指向list(此时list不再指向列表中的第一个元素,即违反了不变量),但是list还没有指向l(在第18行重新建立)。
正确使用锁可以确保每次只有一个CPU可以对临界区域中的数据结构进行操作,因此当数据结构的不变量不成立时,将没有其他CPU对数据结构执行操作。锁可以视为串行化并发的临界区域,以便同时只有一个进程在运行这部分代码,从而维护不变量(假设临界区域设定了正确的隔离性)。还可以将由同一锁保护的临界区域视为彼此之间的原子,即彼此之间只能看到之前临界区域的完整更改集,而永远看不到部分完成的更新。
尽管正确使用锁可以改正不正确的代码,但锁限制了性能。例如,如果两个进程并发调用kfree,锁将串行化这两个调用。如果多个进程同时想要相同的锁或者锁经历了争用,则称之为发生冲突(conflict)。内核设计中的一个主要挑战是避免锁冲突。xv6为此几乎没做任何工作,但是复杂的内核会精心设计数据结构和算法来避免锁的争用。在链表示例中,内核可能会为每个CPU维护一个空闲列表,并且只有当CPU的列表为空并且必须从另一个CPU挪用内存时才会触及另一个CPU的空闲列表。其他用例可能需要更复杂的设计。
我们想要获得更好的性能,那么我们需要有更多的锁,但是这又引入了大量的工作。通常来说,开发的流程是:
- 先以coarse-grained lock(注,也就是大锁)开始。
- 再对程序进行测试,来看一下程序是否能使用多核。
- 如果可以的话,那么工作就结束了,你对于锁的设计足够好了;如果不可以的话,那意味着锁存在竞争,多个进程会尝试获取同一个锁,因此它们将会序列化的执行,性能也上不去,之后你就需要重构程序。
在上述流程中,测试的过程比较重要。有可能模块使用了coarse-grained lock,但是它并没有经常被并行的调用,那么其实就没有必要重构程序,因为重构程序设计到大量的工作,并且也会使得代码变得复杂。所以如果不是必要的话,还是不要进行重构。
Code: Locks
锁就是一个对象,就像其他在内核中的对象一样。有一个结构体叫做lock,它包含了一些字段,这些字段中维护了锁的状态。锁有非常直观的API:
- acquire,接收指向lock的指针作为参数。acquire确保了在任何时间,只会有一个进程能够成功的获取锁。
- release,也接收指向lock的指针作为参数。在同一时间尝试获取锁的其他进程需要等待,直到持有锁的进程对锁调用release。
锁的acquire和release之间的代码,通常被称为临界区域(critical section)。之所以被称为critical section,是因为通常会在这里以原子的方式执行共享数据的更新。所以基本上来说,如果在acquire和release之间有多条指令,它们要么会一起执行,要么一条也不会执行。所以永远也不可能看到位于critical section中的代码,如同在race condition中一样在多个CPU上交织的执行,所以这样就能避免race condition。
现在的程序通常会有许多锁,这样就能获得某种程度的并发执行。xv6有两种类型的锁:自旋锁(spinlocks)和睡眠锁(sleep-locks)。
xv6将自旋锁表示为struct spinlock (kernel/spinlock.h:2)。结构体中的重要字段是locked,当锁可用时为零,当它被持有时为非零。从逻辑上讲,xv6应该通过执行以下代码来获取锁:
1
2
3
4
5
6
7
8
9
10
void
acquire(struct spinlock* lk) // does not work!
{
for(;;) {
if(lk->locked == 0) {
lk->locked = 1;
break;
}
}
}
不幸的是,这种实现不能保证多处理器上的互斥。可能会发生两个CPU同时到达第5行,看到lk->locked为零,然后都通过执行第6行占有锁。此时就有两个不同的CPU持有锁,从而违反了互斥属性。我们需要的是一种方法,使第5行和第6行作为原子(即不可分割)步骤执行。因为锁被广泛使用,多核处理器通常提供实现第5行和第6行的原子版本的指令。在RISC-V上,这个特殊的指令就是amoswap(atomic memory swap)。这个指令接收3个参数,分别是address,寄存器r1,寄存器r2。这条指令会先锁定住address,将address中的数据保存在一个临时变量中(tmp),之后将r1中的数据写入到地址中,之后再将保存在临时变量中的数据写入到r2中,最后再对于地址解锁。通过这里的加锁,可以确保address中的数据存放于r2,而r1中的数据存放于address中,并且这一系列的指令打包具备原子性。
kernel/spinlock.h
1
2
3
4
5
6
7
8
// Mutual exclusion lock.
struct spinlock {
uint locked; // Is the lock held?
// For debugging:
char *name; // Name of lock.
struct cpu *cpu; // The cpu holding the lock.
};
kernel/spinlock.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
// Mutual exclusion spin locks.
#include "types.h"
#include "param.h"
#include "memlayout.h"
#include "spinlock.h"
#include "riscv.h"
#include "proc.h"
#include "defs.h"
void
initlock(struct spinlock *lk, char *name)
{
lk->name = name;
lk->locked = 0;
lk->cpu = 0;
}
// Acquire the lock.
// Loops (spins) until the lock is acquired.———>所谓自旋(spin),也就是在获得锁之前一直重试
void
acquire(struct spinlock *lk)
{
push_off(); // disable interrupts to avoid deadlock.
if(holding(lk))
panic("acquire");
// On RISC-V, sync_lock_test_and_set turns into an atomic swap:
// a5 = 1
// s1 = &lk->locked
// amoswap.w.aq a5, a5, (s1)
// 这个函数会将lk->locked的值设为1,并返回之前的值,如果之前的值为0,说明锁未被占用,获取锁
// 成功,否则需要不断循环获取锁,直到获取成功为止。
while(__sync_lock_test_and_set(&lk->locked, 1) != 0)
;
// Tell the C compiler and the processor to not move loads or stores
// past this point, to ensure that the critical section's memory
// references happen strictly after the lock is acquired.
// On RISC-V, this emits a fence instruction.
// 在获取锁成功后,代码使用__sync_synchronize()函数来确保在临界区内的内存访问发生在锁被获
// 取之后。这是因为在多处理器或多线程环境下,不同的CPU或线程可能会对内存进行乱序访问,如果不
// 加控制,可能会导致内存访问的顺序与程序中的顺序不一致,从而导致程序出现错误。
// __sync_synchronize()函数可以告诉编译器和处理器不要将锁之后的内存访问指令移动到锁之前,
// 从而确保内存访问的顺序正确。
__sync_synchronize();
// Record info about lock acquisition for holding() and debugging.
lk->cpu = mycpu();
}
// Release the lock.
void
release(struct spinlock *lk)
{
if(!holding(lk))
panic("release");
lk->cpu = 0;
// Tell the C compiler and the CPU to not move loads or stores
// past this point, to ensure that all the stores in the critical
// section are visible to other CPUs before the lock is released,
// and that loads in the critical section occur strictly before
// the lock is released.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();
// Release the lock, equivalent to lk->locked = 0.
// This code doesn't use a C assignment, since the C standard
// implies that an assignment might be implemented with
// multiple store instructions.
// On RISC-V, sync_lock_release turns into an atomic swap:
// s1 = &lk->locked
// amoswap.w zero, zero, (s1)
__sync_lock_release(&lk->locked);
pop_off();
}
// Check whether this cpu is holding the lock.
// Interrupts must be off.
int
holding(struct spinlock *lk)
{
int r;
r = (lk->locked && lk->cpu == mycpu());
return r;
}
// push_off/pop_off are like intr_off()/intr_on() except that they are matched:
// it takes two pop_off()s to undo two push_off()s. Also, if interrupts
// are initially off, then push_off, pop_off leaves them off.
// 这段代码实现了一个可嵌套的中断禁用机制,可以用来保护临界区。在这个机制中,push_off()函数用
// 来禁用中断,pop_off()函数用来恢复中断状态。这两个函数都会记录禁用中断的嵌套层数,以确保每个
// push_off()都要对应一个pop_off()。
// 这种可嵌套的中断禁用机制可以保护临界区,避免多个线程同时访问共享数据。在进入临界区之前,调用
// push_off()函数禁用中断,然后在离开临界区时调用pop_off()函数恢复中断状态。这样可以确保在临
// 界区中不会被中断打断,从而保证数据的正确性。
// 在push_off()中,首先保存当前中断状态,然后禁用中断。如果当前没有禁用中断,则将保存的中断状
// 态保存到当前CPU的intena字段中,表示中断原本的状态。然后将noff字段加1,表示进入了一个新的禁
// 用中断的嵌套层次。
void
push_off(void)
{
int old = intr_get();
intr_off();
if(mycpu()->noff == 0)
mycpu()->intena = old;
mycpu()->noff += 1;
}
// 在pop_off()中,首先检查当前中断是否被禁用,如果没有禁用,则表示代码存在问题,会触发panic。
// 然后检查当前CPU的noff字段,如果小于1,则表示代码存在问题,也会触发panic。然后将noff字段减
// 1,表示退出了一个禁用中断的嵌套层次。如果当前CPU的noff字段为0,并且原本中断是开启的,则恢复
// 中断状态。这里的intr_on()函数用来开启中断。
void
pop_off(void)
{
struct cpu *c = mycpu();
if(intr_get())
panic("pop_off - interruptible");
if(c->noff < 1)
panic("pop_off");
c->noff -= 1;
if(c->noff == 0 && c->intena)
intr_on();
}
Code: Using locks
xv6在许多地方使用锁来避免race conditions,kalloc和kfree就是一个很好的例子。使用锁的一个困难是决定要使用多少锁,以及每个锁应该保护哪些数据和不变量,有几个基本原则:
为了提高效率,不要向太多地方上锁是很重要的,因为锁会降低并行性。如果并行性不重要,那么可以安排只拥有一个线程,而不用担心锁。一个简单的内核可以在多处理器上做到这一点,方法是拥有一个锁,这个锁必须在进入内核时获得,并在退出内核时释放(尽管如管道读取或wait的系统调用会带来问题)。许多单处理器操作系统已经被转换为使用这种方法在多处理器上运行,有时被称为“大内核锁(big kernel lock)”,大内核锁是一种简单而有效的并发控制方法,但它会导致性能瓶颈,因为在任何时候只有一个CPU可以访问内核。为了提高性能,许多操作系统已经转向使用细粒度锁,这些锁可以让多个CPU同时访问内核的不同部分,从而提高并行性。这些细粒度锁通常是基于特定的数据结构或资源来设计的,例如自旋锁、读写锁、互斥锁等。使用这些锁需要更复杂的并发控制技术,但可以提高系统的并行性和性能。
粗粒度锁的一个例子:xv6的kalloc.c分配器有一个由单个锁保护的空闲列表。如果不同CPU上的多个进程试图同时分配页面,每个进程在获得锁之前将必须在acquire中自旋等待。自旋会降低性能,因为它只是无用的等待。如果对锁的争夺浪费了很大一部分CPU时间,也许可以通过改变分配器的设计来提高性能,使其拥有多个空闲列表,每个列表都有自己的锁,以允许真正的并行分配。
细粒度锁定的一个例子:xv6对每个文件都有一个单独的锁,这样操作不同文件的进程通常可以不需等待彼此的锁而继续进行。文件锁的粒度可以进一步细化,以允许进程同时写入同一个文件的不同区域。最终的锁粒度决策需要由性能测试和复杂性考量来驱动。
下表列出了xv6中的所有锁。

Deadlock and lock ordering
如果在内核中执行的代码路径必须同时持有数个锁,那么所有代码路径以相同的顺序获取这些锁是很重要的。如果它们不这样做,就有死锁的风险。假设xv6中的两个代码路径需要锁A和B,但是代码路径1按照先A后B的顺序获取锁,另一个路径按照先B后A的顺序获取锁。假设线程T1执行代码路径1并获取锁A,线程T2执行代码路径2并获取锁B。接下来T1将尝试获取锁B,T2将尝试获取锁A。两个获取都将无限期阻塞,因为在这两种情况下,另一个线程都持有所需的锁,并且不会释放它,直到它的获取返回。为了避免这种死锁,所有代码路径必须以相同的顺序获取锁。
在xv6操作系统中,由于sleep函数的工作方式,每个进程需要持有一个锁来保护其状态和资源。这些锁通常是包含在struct proc结构体中的。在一些情况下,多个进程需要共享同一个资源,例如控制台输入。为了确保对共享资源的访问是正确的和同步的,xv6使用了锁顺序链来保证锁的获取顺序。这意味着在获取多个锁时,必须按照特定的顺序获取它们,以避免死锁。例如,在处理控制台输入中断时,consoleintr函数需要获取cons.lock锁来保护控制台输入的状态,然后才能唤醒等待输入的进程。因此,全局避免死锁的锁顺序规则包括必须在任何进程锁之前获取cons.lock锁的规则。这样可以确保在获取多个锁时,锁的获取顺序是正确的,避免了死锁的发生。文件系统代码包含xv6最长的锁链。例如,创建一个文件需要同时持有目录上的锁、新文件inode上的锁、磁盘块缓冲区上的锁、磁盘驱动程序的vdisk_lock和调用进程的p->lock。为了避免死锁,文件系统代码总是按照前一句中提到的顺序获取锁。
遵守全局死锁避免的顺序可能会出人意料地困难。有时锁顺序与逻辑程序结构相冲突,例如,也许代码模块M1调用模块M2,但是锁顺序要求在M1中的锁之前获取M2中的锁。有时锁的身份是事先不知道的,也许是因为必须持有一个锁才能发现下一个要获取的锁的身份。这种情况在文件系统中出现,因为它在路径名称中查找连续的组件,也在wait和exit代码中出现,因为它们在进程表中寻找子进程。最后,死锁的危险通常是对细粒度锁定方案的限制,因为更多的锁通常意味着更多的死锁可能性。避免死锁的需求通常是内核实现中的一个主要因素。
Locks and interrupt handlers
在xv6操作系统中,自旋锁被用来保护多个线程和中断处理程序共享的数据。当一个中断处理程序需要访问被自旋锁保护的数据时,它必须遵循一些特定的规则,以避免死锁和其他并发控制问题。如果一个自旋锁被中断处理程序所使用,那么CPU必须保证在启用中断的情况下永远不能持有该锁。因此,xv6在获取任何锁时,总是禁用该CPU上的中断。这样可以确保在持有锁的情况下不会发生中断,避免了死锁的发生。
在xv6中,获得自旋锁需要先关闭中断,这是因为自旋锁是一种基于忙等待的锁,其本质是在循环中不断检查锁的状态,直到获得锁为止。如果在获得自旋锁的过程中,中断被触发并且中断处理程序也需要获得同一个锁,那么就会出现两个问题:
中断处理程序会打断当前进程的执行,可能会导致当前进程永远无法获得锁,从而造成死锁。
中断处理程序和当前进程同时竞争同一个锁,如果不同步它们之间的访问,就会导致数据不一致的问题。
因此,在获得自旋锁之前,需要先关闭中断,以避免中断处理程序和当前进程之间的竞争,并确保能够安全地获得锁。
当CPU未持有自旋锁时,xv6重新启用中断。为了处理嵌套的临界区域,它必须做一些记录,以便在释放锁时恢复最外层临界区域开始时存在的中断使能状态。具体地,acquire调用push_off来禁用中断,并将当前CPU上锁的嵌套级别加1;而release调用pop_off来将当前CPU上锁的嵌套级别减1,并在嵌套级别为0时恢复中断使能状态。在这个过程中,intr_off和intr_on函数执行RISC-V指令分别用来禁用和启用中断。
需要注意的是,严格的在设置lk->locked之前让acquire调用push_off是很重要的。如果两者颠倒,会存在一个既持有锁又启用了中断的短暂窗口期,不幸的话定时器中断会使系统死锁。同样,只有在释放锁之后,release才调用pop_off也是很重要的。这些规则的遵守可以确保在多线程和中断处理程序并发访问共享资源时,锁的获取和释放顺序是正确的,避免了死锁和其他并发控制问题的发生。
Instruction and memory ordering
一点体系结构的知识
体系结构中我们知道编译器和CPU为了获得更高的性能而不按顺序执行代码,例如前递、指令调度、保留站等技术。编译器和CPU在重新排序时需要遵循一定规则,以确保它们不会改变正确编写的串行代码的结果。然而,规则确实允许重新排序后改变并发代码的结果,并且很容易导致多处理器上的不正确行为。例如,在push的代码中,如果编译器或CPU将对应于第4行的存储指令移动到第6行release后的某个地方,那将是一场灾难:
1
2
3
4
5
6
l = malloc(sizeof *l);
l->data = data;
acquire(&listlock);
l->next = list;
list = l;
release(&listlock);
如果发生这样的重新排序,将会有一个窗口期,另一个CPU可以获取锁并查看更新后的list,但却看到一个未初始化的list->next。为了告诉硬件和编译器不要执行这样的重新排序,xv6在acquire和release中都使用了_sync_synchronize(),它告诉编译器和CPU不要跨障碍重新排序load或store指令。
Sleep locks
自旋锁的缺点是当持有锁的进程需要长时间等待时,其他进程会在自旋时浪费很长时间的CPU,并且持有锁的进程不能让出CPU。因此,xv6提供了睡眠锁,它可以在等待获取锁时让出CPU,并允许在持有锁时让步(以及中断)。睡眠锁会使用自旋锁保护锁定字段,但是acquiresleep会原子地让出CPU并释放自旋锁,这样其他线程可以在等待时执行。需要注意的是,由于睡眠锁保持中断使能,所以它们不能用在中断处理程序中。同时,由于acquiresleep可能会让出CPU,睡眠锁不能在自旋锁临界区域中使用。因此,自旋锁适用于短的临界区域,而睡眠锁适用于长时间的操作。
kernel/sleeplock.h
1
2
3
4
5
6
7
8
9
// Long-term locks for processes
struct sleeplock {
uint locked; // Is the lock held?
struct spinlock lk; // spinlock protecting this sleep lock
// For debugging:
char *name; // Name of lock.
int pid; // Process holding lock
};
kernel/sleeplock.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
// Sleeping locks
#include "types.h"
#include "riscv.h"
#include "defs.h"
#include "param.h"
#include "memlayout.h"
#include "spinlock.h"
#include "proc.h"
#include "sleeplock.h"
void
initsleeplock(struct sleeplock *lk, char *name)
{
initlock(&lk->lk, "sleep lock");
lk->name = name;
lk->locked = 0;
lk->pid = 0;
}
void
acquiresleep(struct sleeplock *lk)
{
acquire(&lk->lk);
while (lk->locked) {
sleep(lk, &lk->lk);
}
lk->locked = 1;
lk->pid = myproc()->pid;
release(&lk->lk);
}
void
releasesleep(struct sleeplock *lk)
{
acquire(&lk->lk);
lk->locked = 0;
lk->pid = 0;
wakeup(lk);
release(&lk->lk);
}
int
holdingsleep(struct sleeplock *lk)
{
int r;
acquire(&lk->lk);
r = lk->locked && (lk->pid == myproc()->pid);
release(&lk->lk);
return r;
}
从代码看睡眠锁的精髓是sleep和wakeup来控制的。